AI's open source summer revolution

It’s summertime and the living is easy. Unless, that is, you’re trying to keep up with events in the AI world. If you thought you could take a week’s holiday without missing some paradigm-shifting event, think again.
The last couple of weeks have seen a flurry of announcements and developments, forcing this one relaxed holidaymaker out of vacation mode and back into blogging mode. Let’s dive into it.
- Meta releases Llama 3.1, including a 405B parameter model rivalling proprietary heavy weights.
- Mistral unveils two new models: the powerful Mistral Large 2 and the developer-friendly Mistral Nemo.
- Ollama introduces native support for function calling, enhancing local LLM capabilities.
For developers, builders and AI enthusiasts, there’s some juicy stuff in here. So let’s take a deeper dive into what’s new.
Meta launches Llama 3.1 models
The big news came from Meta, who have released new versions of Llama 3, with increased context size (128k), better multilingual abilities and tool calling.

This includes the release of a new 405B parameter model that offers “frontier level” capabilities - performance that was previously only available in the most advanced proprietary models like GPT-4o and Sonnet 3.5.
When I started this blog - only seven months ago - GPT-4 was a country mile ahead of everyone else. Now, not only have other proprietary models caught up (and overtaken), for the first time frontier level LLM capabilities are available to everyone to work with and build on.
This really is a huge moment. Mark Zuckerberg writes about the philosophy and arguments in favour of open source AI, and there’s a fair amount of strategy at play here too. All eyes now turn to OpenAI to see if they have any GPT-5 shaped tricks up their sleeve, or if their moat truly has evaporated.
Of course, unless you have a small GPU cluster in your garage, you or I won’t be able to run the 405B model at home. Luckily, Llama 3.1 also comes in 8B and 70B parameter sized versions for us to prompt, RAG, fine-tune, optimise and just generally have fun with.
If you want to try the 405B model, the easiest place is probably to hop on to Hugging Chat (unless you’re an EU citizen, in which case, VPN is your friend). The smaller 8B and 70B models are widely available on popular chat platforms, or can be downloaded from Hugging Face or Ollama.
Mistral launches two new models
In a case of exceptionally poor timing, whilst everyone was talking about the Llama 3.1 news, Mistral have also launched two new models that risk being overlooked, but definitely shouldn’t be.
Mistral Large 2 is a 123B parameter model, with 128k context size, significantly improved capabilities and impressive benchmarks all-round. Following on from Mistral’s work on Codestral, they claim Mistral Large 2 compares favourably to Llama 3.1 405B in Maths and Coding.
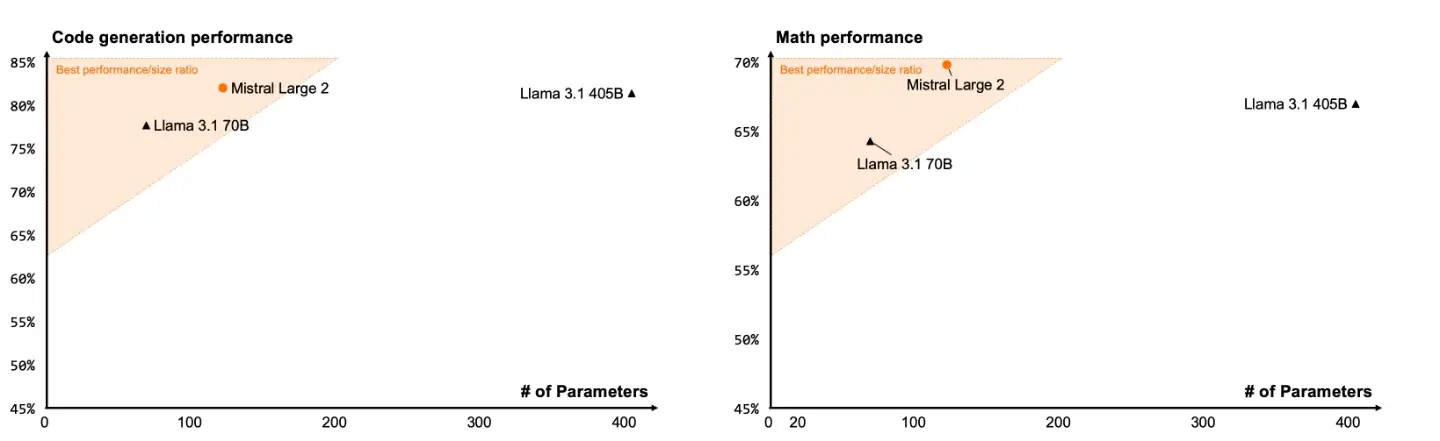
More exciting to me than the large model, is its little sibling Mistral Nemo, a new 12B parameter model with 128k context size, built in collaboration with NVIDIA with an entirely permissive licence, and looks to be an absolute banger for its size category. This is a drop-in replacement for Mistral 7B, and will be sure to keep the fine-tune community busy over the coming months.
Ollama function calling
One thing Llama 3.1 and the new Mistral models have in common is significantly improved support for tool use and function calling, built in to the model’s training. Which is all very convenient because my favourite tool for running LLMs locally, Ollama, has shipped version 0.3 with first-class support for tool use / function calling.

Until now, it’s been kind of possible to implement function calling with Ollama, but the models weren’t really explicitly trained for it and the implementation involved too much double-sided sticky tape for my liking.
This release makes tool use a first-class feature of Ollama, supported in both its own chat API and the OpenAI-compatible endpoint. Combined with new models that are explicitly trained to handle tool use, all of a sudden the prospect of plugging local models into agentic systems is no longer a pipe dream.
Time to build
If you’re a developer, and you’re building with large language models, what a couple of weeks! The big picture is that for the first time, state of the art, frontier LLM capabilities are available to everyone to use and build on. But it’s not just a case of the bigger models getting bigger and better, the smaller models are improving too. Models that anyone can run on their local computer are as capable today as the leading proprietary models were a year ago.
With the capabilities of models improving across all size categories, and the tooling and dev infrastructure improving all the time, doors to opportunities open up that just weren’t possible a few months ago.
It’s a great time to be building in this space. I had to jump out of holiday mode to tell you this, but now I need to get coding. There’s stuff to build!