Discovering lesser-known LLMs with Hugging Face

Last time round, we discovered that creating custom made chatbots in Ollama is wonderfully simple - all it took was editing the SYSTEM prompt in a Modelfile. The world of Ollama offers dozens of models to tinker with, but what if I told you there is a place where there is a seemingly endless stream of unique, weird and wonderful LLMs waiting to be explored.
In the first of this two-part post, I will introduce you to the online heart and soul of everything AI - the curiously named Hugging Face - and we’ll use it to discover those lesser-known LLMs; in part two we’ll dive back into Modelfiles and learn how to import these newfound models into Ollama.
Hugging what?
Named after the 🤗 emoji, I would guess without the input of too many branding consultants, Hugging Face can be thought of as the “GitHub of AI”. At its core, it hosts repositories containing models and datasets for natural language processing, computer vision, audio, and anything machine learning related.
On top of that, Hugging Face allows users to publish posts and discussions, offers compute services to train and fine-tune your own models, and has a feature called “Spaces” which allows its community to run ML related apps and services on their infrastructure. There is also Hugging Chat, a ChatGPT-alike service that exclusively uses open source LLMs.
Put all this together, and Hugging Face can be quite a daunting place to navigate for the uninitiated. But it is undoubtedly an active and lively place, and for anyone wanting to have anything to do with AI, this is where it is all happening!
Navigating the wild world of LLMs
Navigating the myriad of new models constantly appearing on Hugging Face first requires taking a step back and understanding structurally how this open source LLM ecosystem is made up.
Base models
Creating a new LLM from scratch is a complex and compute intensive thing to do. We know that training Llama 2 involved running 6,000 GPUs for a couple of weeks at a cost of around $2M. There are a few large tech companies and well-funded AI research companies doing this in the open, including:
- Meta - creators of the Llama 2 models
- Mistral AI - behind the Mistral and Mixtral models
- 01.ai - Chinese company behind the Yi models
- Upstage AI - creators of the Solar models
Llama 2 isn’t just a single model - it comes in various sizes: 7b, 13b and 70b. This refers to the number of parameters (also known as weights) the model has been trained on. Larger means more parameters and generally this should result in a more capable, intelligent and knowledgable model, but requires more system resources to run.
In addition, Llama 2 comes in two variations - the base model and a “chat” version. So what’s going on here?
Remember, an LLM is a language model that is trained to “complete” text. For example, if you write a prompt “I woke up in the morning, and…”, the base model will complete that phrase with something like ”… combed my hair, brushed my teeth and prepared for the day ahead.” This is all the model is doing - understanding the context of a prompt, and generating a statistically likely sequence of words to complete the pattern, based on its training data.
To create a model you can chat with and have back-and-forth conversation requires further training and fine-tuning, using datasets of chats and Q&As. The result is a “chat” optimised model. Now if you ask it a question, or provide a chat history of messages and responses, the LLM is better trained to respond with the next message in the chat. It is still fundamentally doing the same thing - completing the prompt with a statistically likely pattern based on its training - but that training allows it to recognise that the text it should generate is the next message in a sequence of messages.
You will find other variations like “instruct” which means the base model has been trained on instruction datasets, like “help me proofread this”, or “write a draft for that”. It’s the same principle, just slightly different training.
Franken-merge models
OK, so far so good? We have a few tech companies and research firms creating novel LLMs, they generally come in different sizes, and sometimes have different variations reflecting additional training and fine-tuning. So, search on Hugging Face for “llama 7b” - go on, try it now. You won’t find 2 or 3 different variations, you will find over 8 thousand different models. So, why all the llamas?
This is where the community of Hugging Face come in. Step aside the well-funded tech companies, and enter the amateurs, the enthusiasts and the AI misfits. Whilst training an entirely new LLM is out of the reach of most individuals, this is not the case for fine-tuning. If you have a couple of old GPUs lying around from your crypto mining days, or if you’re prepared to throw a few bucks spinning up some cloud GPUs for a short period, then you are very much able to create your own LLMs by taking an open base model, and merging it with other models or fine-tuning it with different open datasets. And this is something the Hugging Face community do with gusto. Colloquially known as “Franken-merges”, there are more of these models than you will ever be able to keep up with, from models trained for medical purposes, for philosophy and helping with personal relationships, to uncensored and unbiased models, through to the many (I really mean many) models tailored for erotic role play.
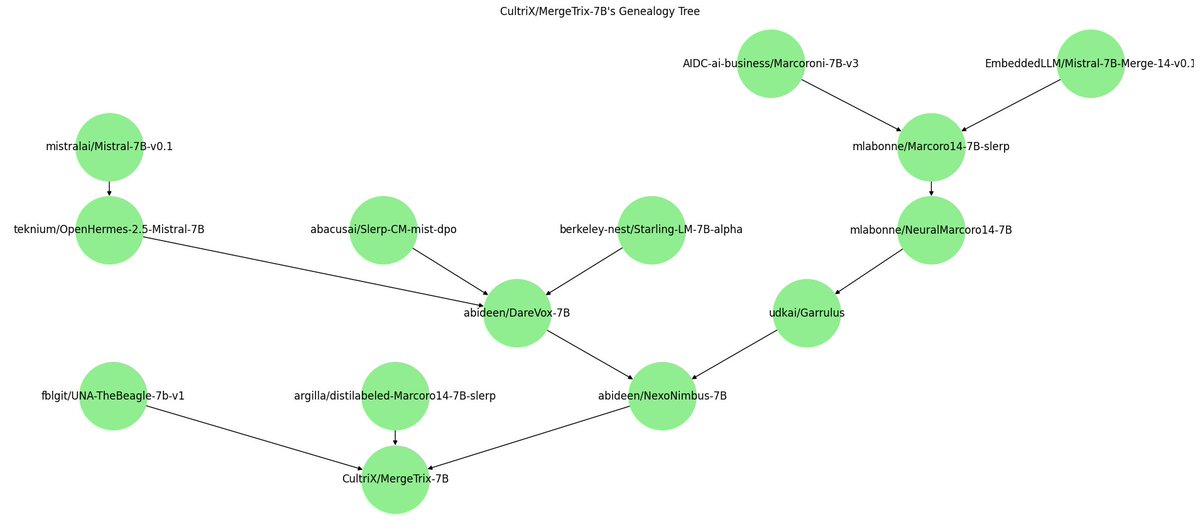
Ultimately, this creates a tree-like structure of LLMs, not unlike how the Linux ecosystem appears. At the top are a few base models, from which are derived a rich and diverse family of interrelated and dependent models.
Quantisation formats and levels
There is one more piece of the jigsaw that we need to understand. To run the models distributed by the original creators will generally involve using Transformers (a Hugging Face library) and manually writing code in Python. Sounds like a fun thing to do in another post, but to use the model with Ollama we need a “quantised” version. Many of the models available on Hugging Face are in fact quantised versions of existing models contributed by different members of the community.
Quantisation is a way to represent the parameters of a model with fewer bits. By reducing the size of each parameter, the model becomes smaller and requires less memory, but comes at the cost of accuracy and precision.
Think of it like you are reducing the resolution of a photograph. You can use a tool like Photoshop to reduce the resolution of an image by 10% or 20%, and reduce its file size without noticeably loosing too much quality and detail. But if you go too far and reduce the resolution too drastically, the image loses its clarity. Quantisation is the same - the goal is to find a happy medium that makes the LLM more accessible to a wider range of hardware, whilst ensuring the drop in quality remains tolerable.

There are a few different formats of quantisation you’ll notice while browsing Hugging Face. GPTQ (GPT Post Training Quantisation) and AWQ (Activation-aware Weight Quantisation) are two formats that focus primarily on GPU inference and performance. Whilst these perform very well, the focus on GPU is a disadvantage if you don’t have the hardware to run them. This is where the GGUF (GPT-Generated Unified Format) format comes in. GGUF, which is what Ollama uses, is a quantisation method that uses the CPU to run the model but also offloads some of its layers to the GPU for a speed-up.
For a much deeper dive into quantisation, I definitely recommend adding Maarten Grootendorst’s excellent article on quantisation methods to your reading lists.
One final thing to bear in mind is that GGUFs themselves come in different shapes and sizes. Model names with the suffix Q3_0, Q4_0, Q5_0 and Q6_0 refer to the quantisation level. Q3 is a 3 bit quantisation and Q6 refers to 6 bits. The lower the number, the more compressed and with greater loss in precision and accuracy. In-between these quantisation levels you may notice finer grain steps like K_S, K_M and K_L (referring to small, medium and large). The K level quantisations generally give you your best tradeoff between size to quality.
I know, it’s complicated. I generally try and find the biggest model that will comfortably run on my machine (Mac Studio M1 Max 32 GB). For 7b-13b models I look for a Q5_K_M, and 34b models I drop to Q4_K_M or even a Q3 if necessary. Depending on your own system, YMMV.
Decoding model file names
This section has been a long-winded way of saying there are a LOT of models to waste your bandwidth on! Browsing Hugging Face, you will find no end of models with long and archaic file names. Whilst there is no standard naming convention, hopefully now you will begin to recognise there are patterns the authors employ in their file names.
For example, CapybaraHermes-2.5-Mistral-7B-GGUF tells us the base model is Mistral 7B, it has been fine-tuned with Capybara and OpenHermes datasets, and it’s a GGUF quantised version. Once you’ve downloaded a few models and read a few model cards, all of this will begin to make sense.
Finding interesting models to play with
Phew! If you made it this far, have a beer 🍻! One question remains: from all of these models and merges and fine-tunes, which ones should you download? Honestly, the best answer to that is to have fun figuring it out yourself. I’d recommend following along at /r/LocalLLaMA which often has discussions about new models, and I’d caution against paying too much attention to the various leaderboards on Hugging Face spaces which are easily gamed by fine-tuning specifically for the leaderboard. For those off-the-beaten track models, make sure you follow TheBloke and LoneStriker who prolifically churn out GGUF quants for all sorts of under-the-radar models.
What’s next?
We’ve covered a lot in this article. We’ve learnt what Hugging Face is, we’re beginning to understand structurally how the open source LLM scene works, and that in this fast moving space there is no shortage of new and interesting models to download and play with.
I encourage you to take a little time getting familiar with the weird and wonderful world of Hugging Face. Find some interesting looking GGUFs to download and get them ready. My next post will be the hands-on fun part. We’ll import your new GGUFs into Ollama and learn some new things about Ollama Modelfiles whilst we’re at it.
Remember to subscribe to the feed and say hello on X. Stay tuned and see you next time.