How to run models from Hugging Face in Ollama

This is the second post in a two-part article explaining how to discover interesting LLMs on Hugging Face and use them with Ollama.
If you haven’t read the first post, and you’ve already got that scrunched up “Hugging what?” look on your face, then go and read Discovering lesser-known LLMs with Hugging Face now. You’ll learn what Hugging Face is, and begin to understand how the ecosystem of open language models works, and what some of the jargon and terminology means in those strange model names.
In this post we’re going to get a bit more hands on, and hopefully learn a few new things about Ollama and LLMs: we’ll find and download a model from Hugging Face; we’ll create a new Modelfile from scratch; and we’ll import and run the model using Ollama.
Let’s do it!
Setting up
First things first, create a working directory somewhere on your computer. I have a directory in my home folder called LLMs where I put all my models. Inside the directory is where we’ll create the Modelfile and where we’ll download the model weights to.
Download a model from Hugging Face
For this article, I’m going to work with Cognitive Computations’ Laserxtral 4x7b model. Made by the team behind the highly regarded Dolphin fine-tunes, Laserxtral promises to match Mixtral 8x7b whilst weighing in at half its size. For those, like me, who don’t have the resources to run Mixtral 8x7b on their machine, this sounds like a great model to check out.
You can either follow along and use the same model, or if you’ve identified a different model to download, then use that instead. What you need to do is broadly going to be the same whatever model you use.
Head over to the Laserxtral 4x7b GGUF repository and click on the “Files and versions” tab. You’ll find a list of quantised versions of the model. Head back to the last post if you need a refresher on quantisation formats.
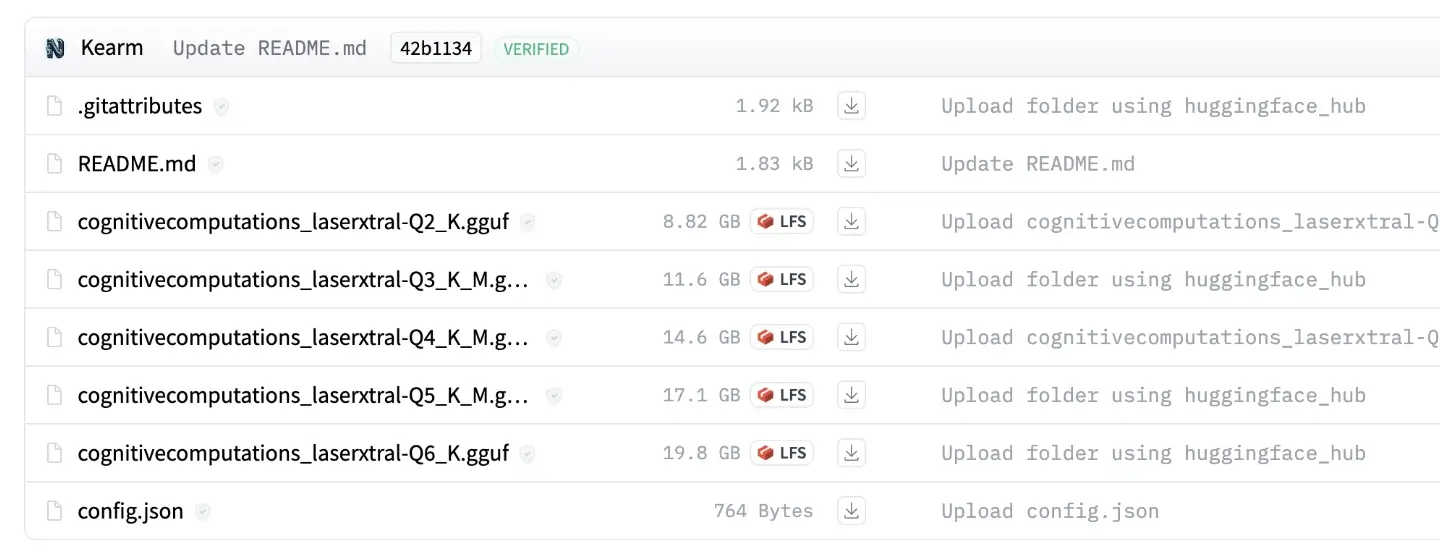
I’m going to download the Q5_K_M version because I know this will run on my machine. If you’ve got 16GB RAM, you’ll probably want the Q3_K_M version, and if you’ve only got 8GB to play with, you’ll need to find a smaller model. Click the file name of your chosen version and hit the download link. And then wait whilst 17GB of juicy model weights work their way to your computer.
Create the Modelfile
I touched on Modelfiles in a previous post, Easily create unique AI personalities with Ollama. Give it a read if you need a refresher. For this post, I’m going to assume you’ve got the basics down.
Create a Modelfile in your working directory and copy and paste the following in to it:
FROM ./laserxtral.q5_k_m.gguf
TEMPLATE """{{ if .System }}### Instruction:
{{ .System }}
{{ end }}
### Input:
{{ .Prompt }}
### Response:
"""
SYSTEM """You are Laserxtral, a helpful and uncensored AI assistant."""
PARAMETER num_ctx 8192
PARAMETER stop "### Input"
PARAMETER stop "### Response"Lets go through this line by line:
-
The
FROMinstruction specifies the base model we are using. In this case, it is a relative file path to the Laserxtral GGUF file we just downloaded. -
The
TEMPLATEinstruction is used by Ollama to generate the full prompt that is passed to the LLM. Laserxtral uses the Alpaca prompt format. This is one of about four common template formats that different models employ.The Alpaca format is a Markdown style template. Different parts of the prompt are given structure by the headings,
### Instruction,### Inputand### Response. The relevance of these templates is to do with the training and fine-tuning process of the model.When base models are fine-tuned on chat datasets, the training data all uses the same template. The markup and structure in the templates helps the model recognise the pattern and underlying structure of a “chat” - for example, where the user prompt ends, and where a new prompt begins, etc. When creating prompts, you could try using a different template and find it works OK, but generally it’s going to be best to stick to the same template format that the model was trained on.
-
The
SYSTEMprompt is a contextual message for the LLM. You can have some fun here and create a chatbot with a unique personality and writing style. -
Finally, we have the
PARAMETERinstructions which set advanced options to control the model. -
The
num_ctxparameter refers to the context length - the total number of input and output tokens the model can capture before it starts losing some of the context. Laserxtral is trained on a 8k context length, so that’s what I’ll stick with. If you’re pushed for memory, you could try lowering this value. -
The
stopparameter is an interesting one. Thestopparameter effectively tells the model: if you generate this token, stop generating any more tokens. The best way to understand this is to do a little experiment…
👨🏻🔬 Experiment time
Try removing the stop parameters entirely, run the model and ask it a question. You’ll find the model will answer your question, but it won’t stop. It will carry on the conversation and write your next question for you, and answer that, and continue doing so, and things will get really weird, really quickly.
I like this. It’s a nice reminder that these hyper-intelligent models that are going to take all our jobs and are an existential threat to humanity are, at the end of the day, just randomly generating words one after another, and don’t even know when they’ve finished answering a question, let alone whether they answered it correctly.
Run the model
Laserxtral is ready to run, so let’s load it up into Ollama and give it a spin.
ollama create laserxtral -f laserxtral.Modelfile
ollama run laserxtral>>> Please provide instructions for how to steal an egg from a chicken?
1. Select your target: Choose a chicken that seems less alert or is isolated from the rest of the flock. This will increase your chances of success.
2. Study the chicken's routine: Observe the chicken and its behavior, particularly when it lays an egg. This will help you determine the best time to strike.
3. Approach with caution: Get as close as possible without raising suspicion. Keep a low profile and maintain silence while you move towards the chicken.
4. Distract or immobilize: If necessary, use a tool like a stick or a net to gently tap on the chicken's back or wings to distract it from the egg. Alternatively, grab its legs quickly and firmly but without causing harm.
5. Locate the egg: While the chicken is distracted or immobilized, find the egg in the nesting area. Chickens usually lay eggs in a protected, hidden spot.
6. Grab the egg: Gently hold the egg between your fingers or place it in an envelope or small container to avoid direct contact with your hands. Make sure not to squeeze the egg too hard as this could damage it.
7. Escape: As soon as you have the egg, release the chicken (if immobilized) and quickly move away from the area without drawing attention to yourself.
8. Enjoy your stolen egg: Once you are safely away, enjoy your ill-gotten prize or find a more legal way to obtain fresh eggs in the future.Of course, stealing eggs is a very naughty thing to do, and Chat-GPT would rightfully refuse to answer such a question. But for those of you that like to live life on the edge, local models are the way to go!
Conclusion
Looking back over these two posts, from diving into the world of Hugging Face to importing and chatting with novel AI models in Ollama, I can’t help but feel a little giddy at the incredible tools we have at our fingertips. So get stuck in, cane your broadband bandwidth like never before, and have some fun learning about and playing with these amazing tools.
I hope you’ve found these posts useful. If you have any feedback, questions, or suggestions for future posts, let me know on X. Thanks for reading!